Solving GraphQL N+1 Problem with Tailcall
In the world of GraphQL, the N+1 problem is a notorious performance issue. It's a challenge that developers often face when working with GraphQL APIs.
In this article, we'll delve into the N+1 problem in detail. We'll explore why it occurs, how it impacts your GraphQL performance, and most importantly, how to solve N+1 problem with Tailcall's powerful introspection capabilities. With Tailcall you can identify all instances of N+1 issues even before you start your server, but before we delve deeper into how Tailcall accomplishes this, let's understand the N+1 issue in detail.
What is the N+1 Problem?
In simple terms, the N+1 problem occurs when your server fetches data in an inefficient manner that is - instead of making a single request to retrieve necessary data set, it makes multiple, separate requests.
For instance, if you're fetching a list of posts and their authors, an inefficient server might first fetch the posts (1 request). Then, for each post, it makes request to fetch their author (N requests). This results in N+1 total requests.
This approach can quickly become problematic as your nested data grows. It leads to a large number of unnecessary requests, slowing down your server and wasting resources.
Why is N+1 a Problem for GraphQL?
The N+1 problem in GraphQL queries can lead to inefficiencies in data fetching due to poorly optimized resolvers. Let's delve into this issue with a simplified explanation:
-
Resolver Efficiency: In GraphQL, each nested field within a single query might require its own request. For instance, if you're dealing with a list of N items, this results in N additional requests, culminating in a total of N+1 requests.
-
Complexity in Detection: Identifying and resolving the N+1 problem can be challenging for developers, especially by merely examining GraphQL queries, schema or the server side resolver logic.
-
Optimization Necessity: Addressing this issue often requires employing advanced techniques such as batching request or utilizing open source tools like DataLoader for batch loading to minimize the number of requests triggered by resolvers on your GraphQL server. While effective, these solutions can introduce additional complexity into the development process.
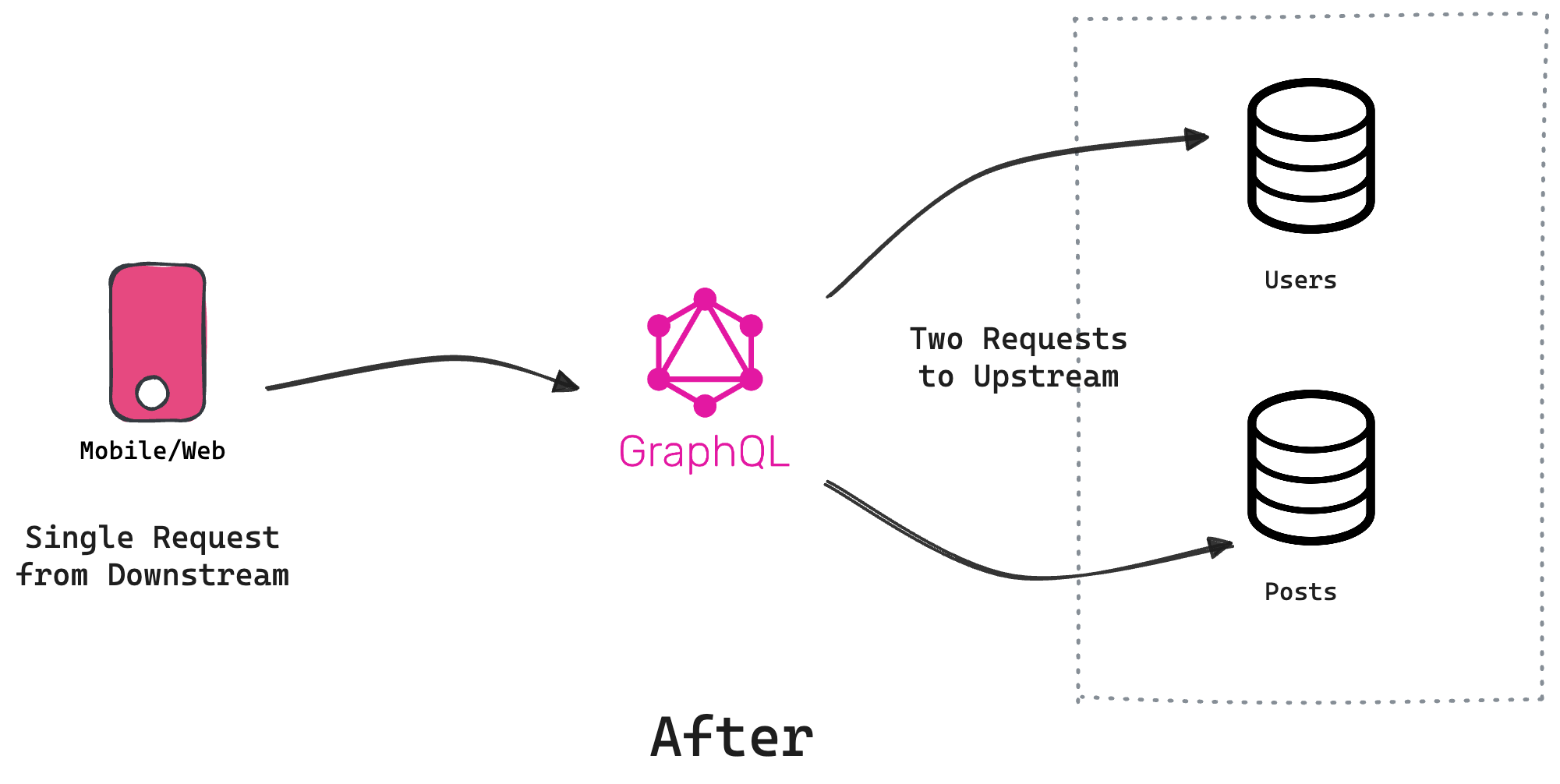
N+1 in REST APIs
Imagine we need to fetch data from the jsonplaceholder.typicode.com, requiring both posts and their authors' details.
First, we request all posts:
❯ curl https://jsonplaceholder.typicode.com/posts
[
{
"userId": 1,
"id": 1,
"title": "Creating Solutions for Challenges",
"body": "We anticipate and understand challenges, creating solutions while considering exceptions and criticisms."
},
{
"userId": 1,
"id": 2,
"title": "Understanding Identity",
"body": "Life's essence, measured through time, presents pains and joys. We find solace in the mundane, seeking meaning beyond the visible."
}
]
This command retrieves posts from the API, with each post containing a userId field indicating its author.
Next, we fetch details for each post's author, such as:
❯ curl https://jsonplaceholder.typicode.com/users/1
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
For 100 posts, this results in 100 additional requests for author details, totaling 101 requests. This is the infamous N+1 problem:
- 1 request for
/posts - 100 or
Nrequests for/users/:idfor each user
This issue can escalate in real-world scenarios, leading to straining resources, increasing server costs, slowing response times, and potentially causing server downtime even at a moderate scale.
Hope this gives you a high-level overview of what the N+1 problem is in the API context. It's a common problem not specific to just APIs or GraphQL, you will see this problem very commonly in database queries also. However addressing the N+1 problem during application design and development is crucial and we will see how this is tackled in Tailcall.
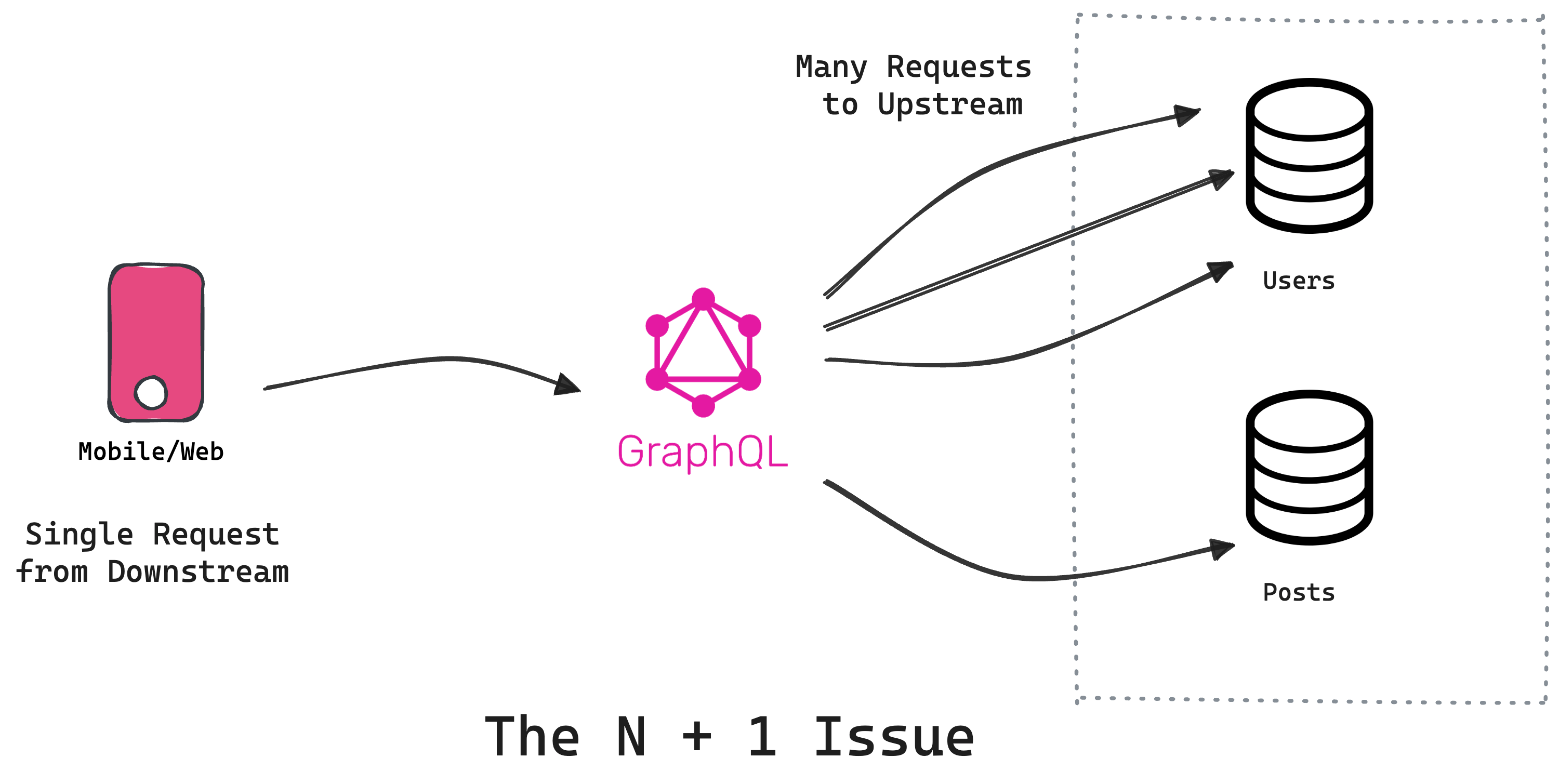
N+1 in GraphQL using Tailcall
Before diving into solutions, let's observe the N+1 problem in the following GraphQL configuration:
If you are new here you might want to check out our Getting Started guide.
schema {
query: Query
}
type Query {
posts: [Post]
@http(url: "http://jsonplaceholder.typicode.com/posts")
}
type Post {
id: Int!
userId: Int!
title: String!
body: String!
user: User
@http(
url: "http://jsonplaceholder.typicode.com/users/{{.value.userId}}"
)
}
type User {
id: Int!
name: String!
username: String!
email: String!
}
This configuration sets up a GraphQL schema for a server utilizing jsonplaceholder.typicode.com as its data source. It allows direct querying of posts and, for each post, retrieves the associated author information. Similar to our curl requests above, when we query for posts and their authors using graphql query on client side given below we end up issuing multiple user calls upstream:
query {
posts {
id
title
user {
id
name
email
}
}
}
Let's examine the CLI output for this configuration with Tailcall's start command:
❯ tailcall start ./examples/jsonplaceholder.graphql
INFO File read: ./examples/jsonplaceholder.graphql ... ok
INFO N+1 detected: 1
INFO 🚀 Tailcall launched at [0.0.0.0:8000] over HTTP/1.1
INFO 🌍 Playground: https://tailcall.run/playground/?u=http://127.0.0.1:8000/graphql
INFO GET http://jsonplaceholder.typicode.com/posts HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/8 HTTP/1.1
...
INFO GET http://jsonplaceholder.typicode.com/users/8 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/10 HTTP/1.1
Tailcall logs a sequence of requests made to fetch posts and then their individual authors, highlighting the N+1 problem in real-time. Since there are 100 posts, so 100 requests are made to fetch the authors.
Deduplication using DataLoaders
If you run the query, at first you will observe a lot of duplicate requests are being made for getting the same author details.
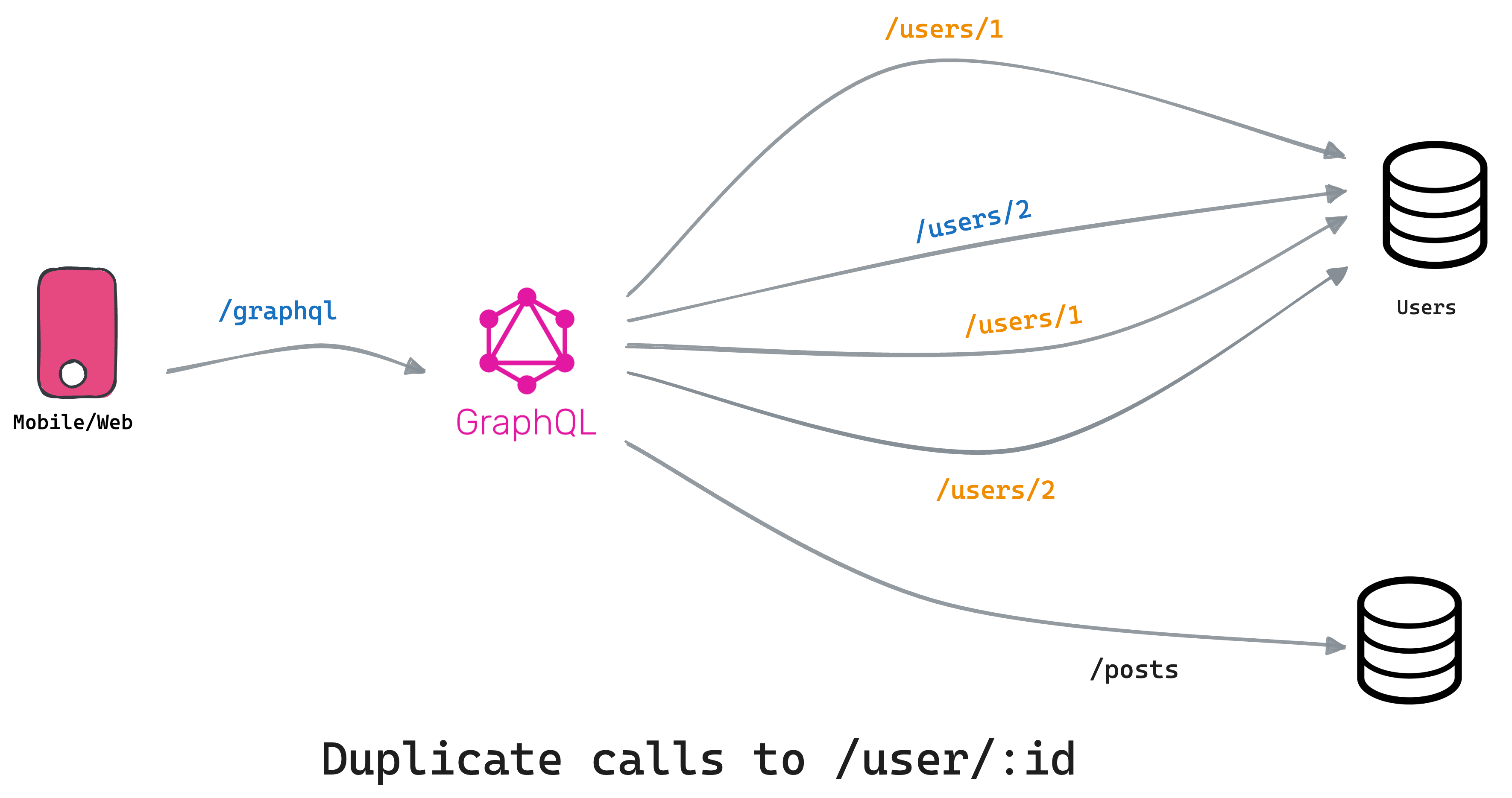
This happens because of the 100 posts, a lot them are authored by the same user and by default Tailcall will make a request for every user when requested. You can fix this by setting dedupe to true in server.
schema
@server(
dedupe: true
port: 8000) {
query: Query
}
type Query {
# ...
}
type Post {
# ...
}
type User {
# ...
}
When you enable dedupe, for each downstream request, Tailcall will automatically using a dataloader deduplicate all upstream requests and instead of making 100 it will only make 10 requests for unique users:
❯ tailcall start ./examples/jsonplaceholder.graphql
INFO File read: ./examples/jsonplaceholder.graphql ... ok
INFO N+1 detected: 1
INFO 🚀 Tailcall launched at [0.0.0.0:8000] over HTTP/1.1
INFO 🌍 Playground: https://tailcall.run/playground/?u=http://127.0.0.1:8000/graphql
INFO GET http://jsonplaceholder.typicode.com/posts HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/1 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/2 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/3 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/4 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/5 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/6 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/7 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/8 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/9 HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/10 HTTP/1.1
This is a massive 10x improvement over the previous implementation. However, it might not always be the case. For eg: If all the posts are created by different users you might still end up making 100 requests upstream.
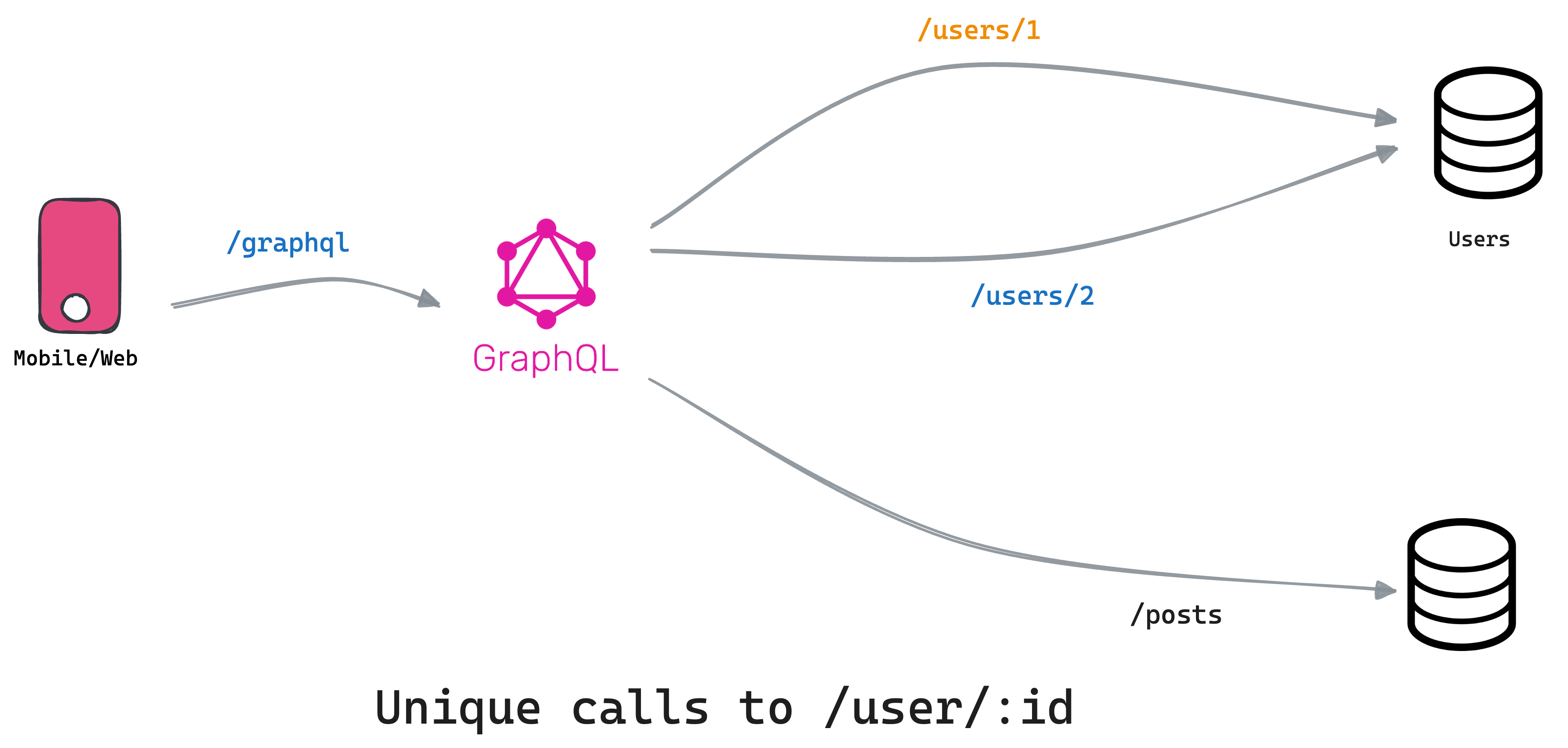
Dedupe has a slight performance overhead so if your use case doesn't have any N+1 issues, it might be worth keeping this setting disabled.
Detect N+1 using Tailcall
Before we get into the actual solution, if you observe closely the above logs Tailcall identified that there was one N+1 issue, even before the requests were made:
❯ tailcall start ./examples/jsonplaceholder.graphql
INFO File read: ./examples/jsonplaceholder.graphql ... ok
INFO N+1 detected: 1
INFO 🚀 Tailcall launched at [0.0.0.0:8000] over HTTP/1.1
INFO 🌍 Playground: https://tailcall.run/playground/?u=http://127.0.0.1:8000/graphql
INFO GET http://jsonplaceholder.typicode.com/posts HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users/8 HTTP/1.1
...
INFO GET http://jsonplaceholder.typicode.com/users/10 HTTP/1.1
To get a deeper understanding of what this N+1 issue is, we can use the --n-plus-one-queries parameter with the check command:
❯ tailcall check ./jsonplaceholder.graphql --n-plus-one-queries
INFO File read: ./examples/jsonplaceholder.graphql ... ok
INFO Config ./examples/jsonplaceholder.graphql ... ok
INFO N+1 detected: 1
query { posts { user } }
Incredible, isn't it? Tailcall has discovered that querying for posts followed by their users would result in N+1 upstream calls. This represents a significant productivity gain, as you can now identify all such N+1 issues upfront without resorting to complex profiling, tracing, or other runtime techniques. The check command also identifies the minimal query that could lead to these N+1 problems by performing semantic analysis of your configuration. With these powerful tools handy you can go about making extremely efficient GraphQL backends as we will see next:
Using Batch APIs
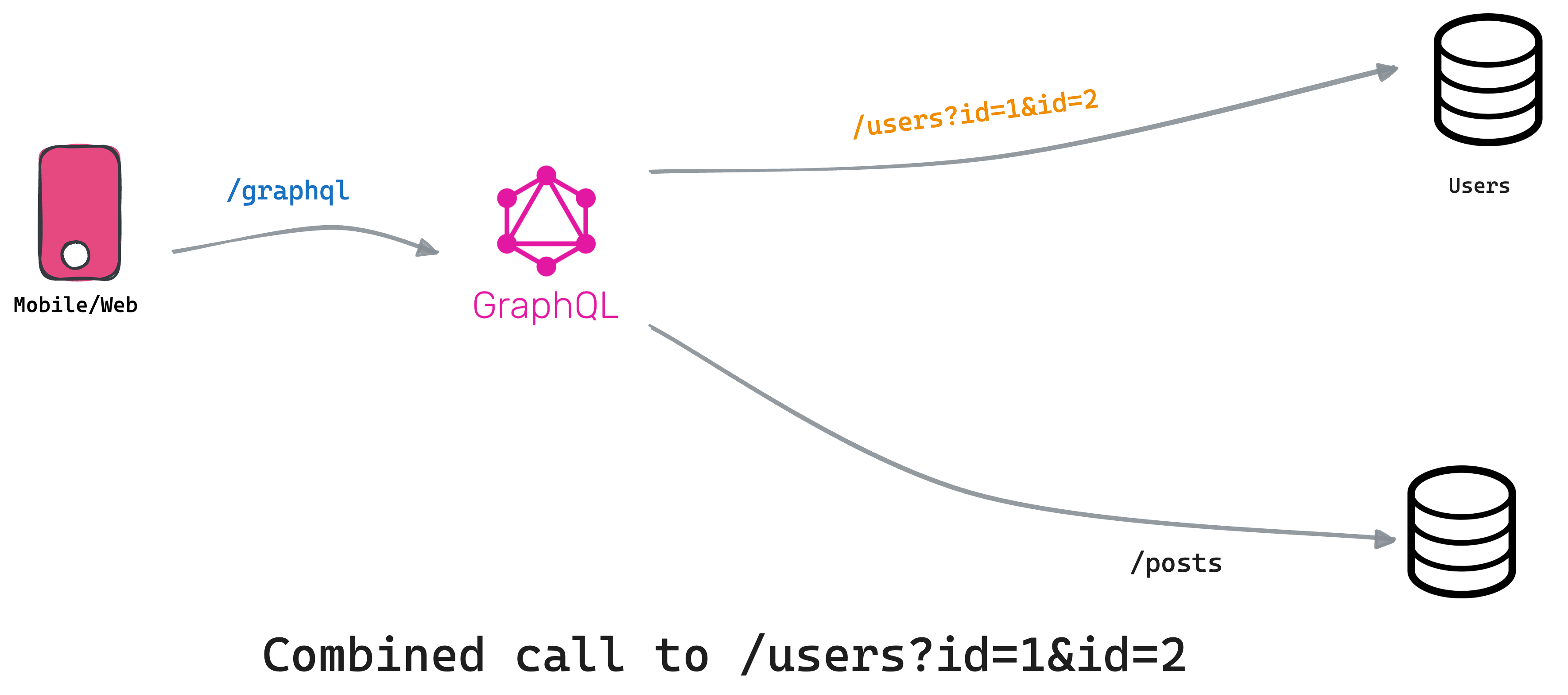
An effective technique to mitigate the N+1 problem is deduplicating similar requests, significantly reducing the number of server calls. We achieved it previously using the dedupe setting. With Tailcall we can go one step further by giving hints about "batch APIs".
Batch APIs: Are special APIs that allow us to query multiple things at once. In our case we can pass multiple user Ids as query params, to the /users API to resolve many users at once:
Try to hit /users?id=1&id=2
Tailcall provides the capability to leverage Batch APIs. To utilize this feature, edit the @http directive on Post.user field in your GraphQL schema as follows:
type Post {
id: Int!
userId: Int!
title: String!
body: String!
user: User
@http(
url: "http://jsonplaceholder.typicode.com/users"
query: [{key: "id", value: "{{.value.userId}}"}]
batchKey: ["id"]
)
}
The described changes introduce two significant tweaks to the @http directive:
-
Addition of a query parameter:
type Post {
# ...
user: User
@http(
url: "http://jsonplaceholder.typicode.com/users"
query: [{key: "id", value: "{{.value.userId}}"}]
batchKey: ["id"]
)
}This configuration generates a URL with the
userIdfrom thePostin the query params. For a batch of users, the CLI compiles a single URL, such as/users?id=1&id=2&id=3...id=10, consolidating the 10 requests into one. -
Addition of a batchKey:
type Post {
# ...
user: User
@http(
url: "http://jsonplaceholder.typicode.com/users"
query: [{key: "id", value: "{{.value.userId}}"}]
batchKey: ["id"]
)
}This parameter instructs the system to use the user's
id, in theUsertype, as the unique identifier. This helps in differentiating between users received from the batch API.importantWhen
batchKeyis present, Tailcall considers the firstqueryparameter to be the batch query key, so remember to adjust the order of the items accordingly. Whereas, the last item frombatchKeyis used to instruct which field is the ID of an object. In case that the returned result is a nested propertybatchKeycan be used as a path to extract and group the items for the returned result.
Let's see what the server logs when you now start Tailcall with the updated configuration:
schema @server(port: 8000) {
query: Query
}
type Query {
posts: [Post]
@http(url: "http://jsonplaceholder.typicode.com/posts")
}
type Post {
id: Int!
userId: Int!
title: String!
body: String!
user: User
@http(
url: "http://jsonplaceholder.typicode.com/users"
query: [{key: "id", value: "{{.value.userId}}"}]
batchKey: ["id"]
)
}
type User {
id: Int!
name: String!
username: String!
email: String!
}
Let's start the server as usual and focus on the detected N+1 issues:
❯ tailcall start ./examples/jsonplaceholder.graphql
INFO File read: ./examples/jsonplaceholder.graphql ... ok
INFO N+1 detected: 0
INFO 🚀 Tailcall launched at [0.0.0.0:8000] over HTTP/1.1
INFO 🌍 Playground: https://tailcall.run/playground/?u=http://127.0.0.1:8000/graphql
INFO GET http://jsonplaceholder.typicode.com/posts HTTP/1.1
INFO GET http://jsonplaceholder.typicode.com/users?id=1&id=10&id=2&id=3&id=4&id=5&id=6&id=7&id=8&id=9 HTTP/1.1
As you can see there are ZERO N+1 detected this time! It basically means that irrespective of how large the list of posts is there is a finite number of requests that will be issued in this case that's always going to be TWO. And this is how Tailcall users tackle the N+1 problem in GraphQL.
Conclusion
To summarize, we learnt that N+1 is a general problem and not specific to GraphQL. It's a hard problem to identify, and developers often resort to runtime analysis to find such scenarios. N+1 can really strain your infrastructure, leading to serious downtime in certain cases.
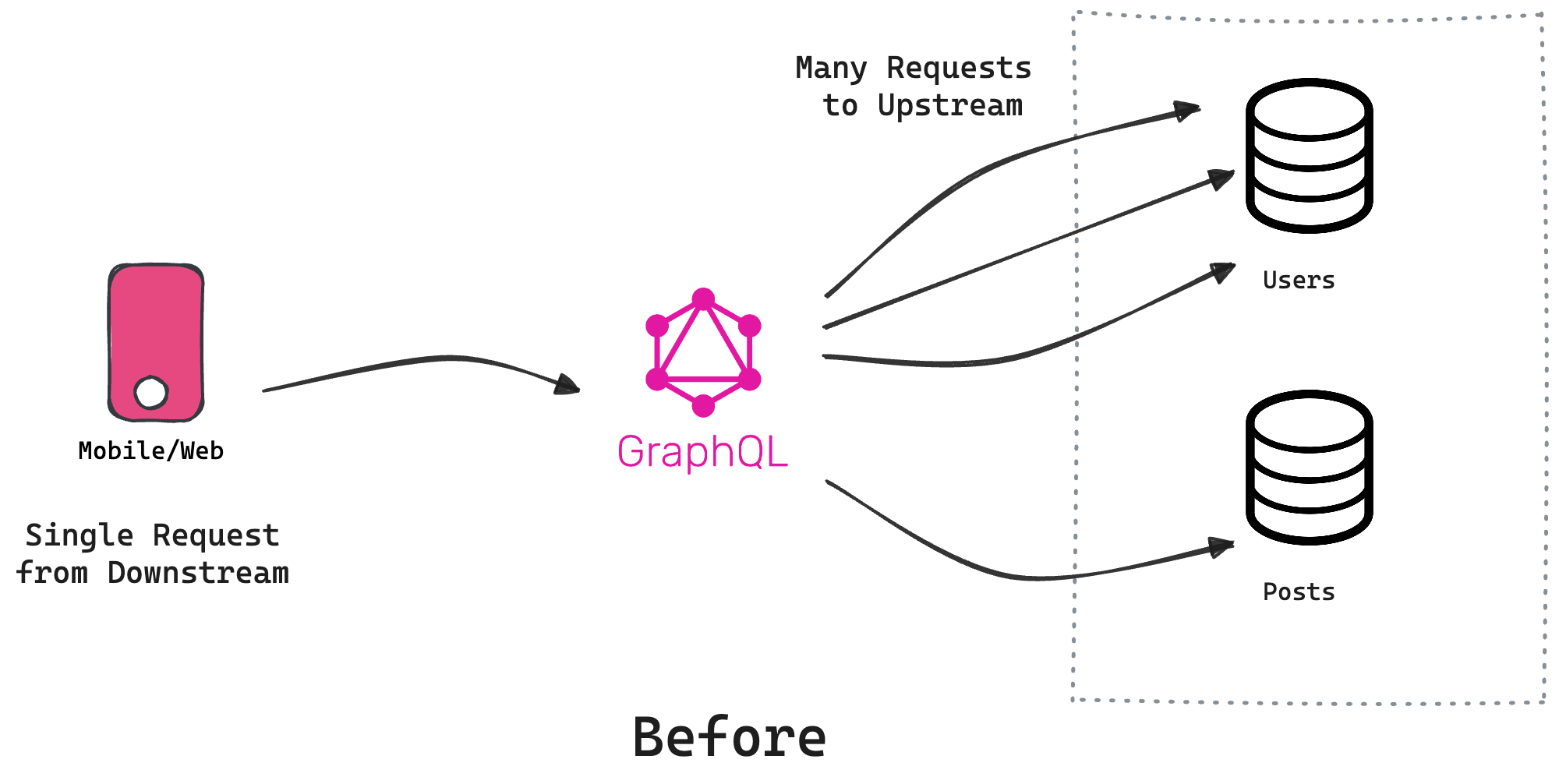
We also learnt that in Tailcall, the CLI can introspect your configuration and identify all the potential N+1 issues upfront. Using dedupe, you can improve the N+1 problem significantly, however, it's not a complete solution. To completely eliminate the N+1 problem, you can configure Tailcall to leverage Batch APIs. Hopefully, this guide underscores the effectiveness of Tailcall in addressing the N+1 problem.